
TL;DR: As a Chapter Lead at Carrefour France, I audit projects across different technical stacks (frontend, backend, mobile, etc.) as part of my role. Recently, I’ve been experimenting with AI agents for these audits. After several audited projects: time reduced by 3x, but not without challenges.
Spoiler: It’s not magic. Be wary of contrary claims. Some come from former no-code gurus now rebranded as “AI evangelists” who pontificate on topics they’ve never even prompted themselves.
I’m sharing my learning journey through iteration, from disillusionment to a working method.
#Why “Vibe Reviewing”?
It’s a nod to “Vibe Coding”: the notion that with a good prompt, you can publish an app to the stores without knowing any frameworks.
Real life involves:
- Long-term app maintenance
- Clean, maintainable code
- No security holes (protecting users in the process)
- Handling load
- Maintaining graphical consistency
In short, real life isn’t:
“Code me GTA VI”, then “Add more cars”, and “Now add a Zombie mode”.
That said, Vibe Coding isn’t worthless. In good hands, with human validation and technical mastery, productivity gains are real.
But a fully vibe-coded app without human oversight can’t be viable today. Especially not long-term.
So why not explore the same approach for code reviews? Agents can structure an audit, provided you know how to guide them.
#🎯 Iteration 0: The Context (Already Established)
Situation: After 3 successful agent-assisted project audits and automating code kata reviews, new challenge: double audit to inform a migration decision.
The Challenge:
- Audit a mobile PoC (40k lines) - evaluate quality, architecture, feasibility for replacing an existing mobile app
- Audit the existing reference mobile app (430k lines) - understand the current state, identify gaps
- Comparative analysis of both to decide: refactor the PoC or rebuild from scratch
The Complexity: 2 different tech stacks, 2 complete parallel audits, a strategic decision to inform.
The Goal: Push my method further on a complex case.
#📝 Iteration 1: The 2-Phase Process (Works… Then Drifts)
Phase 1 - The Plan: Agent-agnostic pre-prompt to generate a structured audit plan with a progress tracking file.
✅ Result: Coherent structure, logical sections, solid framework.
Phase 2 - The Enrichment: For each section, the agent ensures the project builds and runs locally, then installs scanning and quality tools + cross-checks with real figures.
✅ Initial Result: Detailed analyses, concrete metrics, CSV extractions to verify figures.
First Observed Drift: With iterations, the agent loses the initial context. Depending on the LLM model, this can happen quickly, and context compression doesn’t prevent the agent from becoming confused.
Detected Drifts:
- Technical Hallucinations: Agent explained the project used one library when it actually used another
- Pessimistic Estimates: “Migration impossible, start from scratch” without justification, estimates in months rather than weeks
- Inconsistencies Between Sections: Architecture “excellent” on page 5, “problematic” on page 12
👉 First Lesson: Even a good process can drift if pushed too far. Iterate as much as possible on the first plan design prompt, which is the foundation, to avoid returning to it later.
#🤦 Iteration 2: The False Good Idea of Simplification
The Reflex: Facing drift, I decide to “simplify” the audit plan to make it more manageable.
The Fatal Error: By trying to shorten sections and remove “non-essential” steps, I break the structural logic of the initial plan.
Immediate Consequences:
- Loss of Coherence: Sections no longer connect with each other
- Openings for Hallucinations: Agent improvises to fill gaps, repeats itself
- Navigation Difficulty: Impossible to follow the thread, agent gets lost in details
- Loss of Reference Points: Agent doesn’t know where to go, wanders
- Paradoxical Effect: More problems than before “simplification”
It’s like removing load-bearing walls to expand a room.
Back to Square One: I had to return to the complex but stable structure.
👉 Second Lesson: Simplification belongs in execution, not plan architecture. Keep the main structure intact or start over.
#🔍 Iteration 3: Systematic Completion
The Realization: After the simplification failure, I change approach. No more shortening; systematically complete instead.
The Method: Ask the agent to scan all code exhaustively and complete each report section methodically.
The Process:
- Complete Scan: Agent thoroughly examines each file, each module
- Point-by-Point Verification: Systematic cross-checking with actual code
- Gap Filling: Completion of all missing or incomplete sections
- Double-Checking: Agent reviews and validates its own additions
Result: Finally, complete and detailed reports! But…
New Challenge: Reports are individually complete, but global coherence between sections remains problematic. The agent excels in detail but struggles to maintain the overall narrative.
👉 Third Lesson: Section-by-section completion solves the coverage problem but reveals the limits of agents’ global coherence.
#🔧 Iteration 4: Multi-Agent Cross-Validation
The Idea: Have Agent B validate Agent A’s audit to detect hallucinations.
Initial Encouraging Results: Overall, it works well. Cross-validation effectively detects inconsistencies and improves quality.
But Beware of Irony (actually experienced): Asking an agent to find hallucinations… and it creates some by criticizing the other agent’s work! I searched in vain for the hallucinated CVE-9999! 😅
So I stopped using this agent, despite being newly released and free (not for a long time). Harsh jungle law of agents.
Working Methodology:
- Compare 2-3 agents on critical points
- Prioritize human validation on divergences
- The human (me) arbitrates divergences
- Use CSV extractions to arbitrate with figures
- Interactive Dialogue: Chat with the agent having access to the entire code knowledge base to clarify obscure points, explain technical choices, and refine analysis
👉 Fourth Lesson: Cross-validation helps, but remain vigilant about false positives. There will inevitably be misses, especially in long audits.
#🏗️ Iteration 5: Navigation with a Static Site Generator
The Next Step: “We have multiple markdown reports by section. What if we made the audit documentation interactive?”
Architecture Tested with VitePress:
/monorepo
├── /poc-mobile # main code to audit
├── /app-mobile-reference # reference app
├── /documentation
│ ├── /docs # markdown docs
├── {AGENTS}.md # example pre-instructions file at root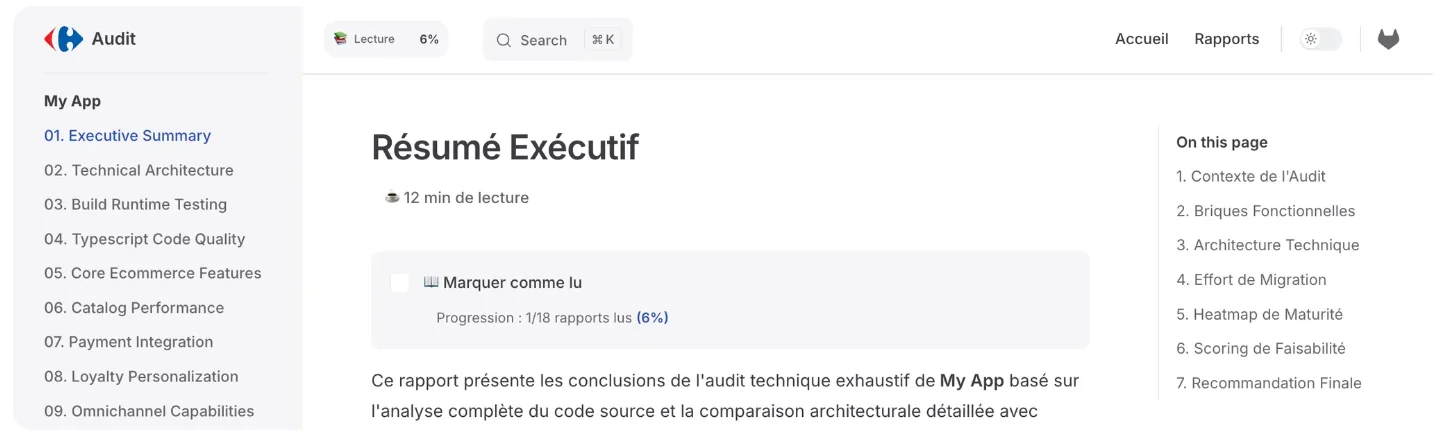
Emerging Features:
- Full-Text Search: Find “security” in 2 seconds across all reports
- Online Editing: Ability to modify docs directly from the site
- Mermaid Diagrams: Architecture automatically visualized and generated as code
- Progress System: Mark sections as “read” with completion badges
- Gamification: Global progress bar, estimated reading time per section
- Automatic Exports: Branded PDF + Markdown (417KB of structured data)
- Dual Advantage: Human-readable AND agent-parsable
👉 Fifth Lesson: Gamifying documentation transforms the audit into a collaborative experience.
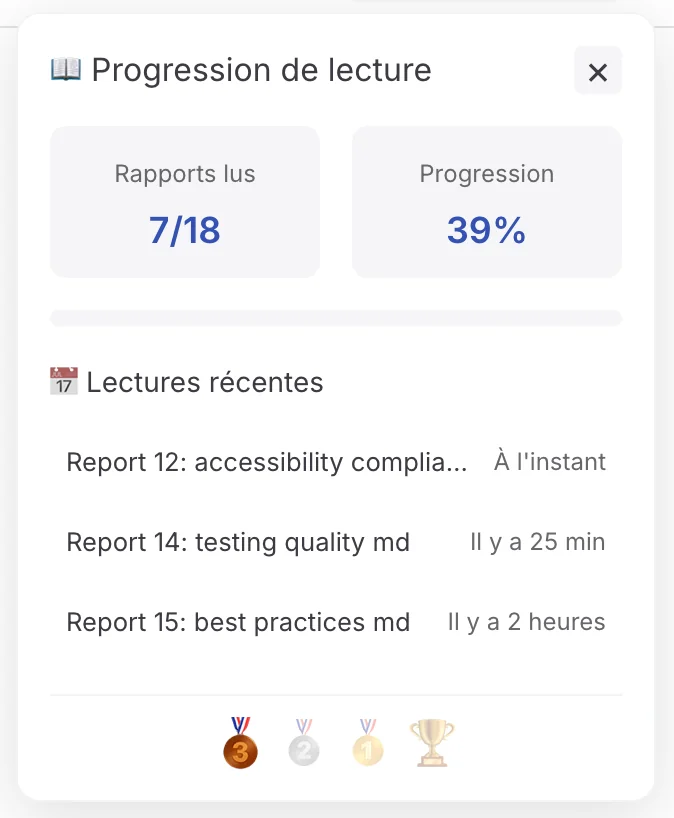
#🔍 Iteration 6: The Documented Arbitrator Agent
A Concrete Case: Two human reviewers disagree on a security risk assessment. One cries critical danger, the other minimizes.
The Unexpected Solution: Delegate research and arbitration to the agent.
The Process:
- Automated Web Collection: Agent directly searches sources online (CVE, official documentation, experience reports, technical GitHub threads, etc.)
- Documented Synthesis: Compilation of current best practices and expert recommendations
- Rigorous Sourcing: Links to official documentation, vulnerability databases, case studies
- Informed Advice: Final recommendation based on collected evidence, not opinion
Result: The agent becomes a documented technical arbitrator that makes decisions based on facts, not assumptions.
Bonus: Automatic knowledge updates - agent accesses the most recent information, not limited to an LLM’s knowledge base that may date back up to 6 months.
👉 Sixth Lesson: AI excels as an objective arbitrator when humans get bogged down in biases.
#🎯 Iteration 7: Standardization and Complete Automation
The Final Goal: Automate end-to-end, from audit to multi-format delivery.
Formatting Instructions in the Pre-Instructions File:
# Audit Pre-instructions
- Standardized output format: Markdown with YAML frontmatter
- Mandatory sections: Architecture, Security, Performance, Tests
- Exports: CSV for metrics + Mermaid diagramsComplete Automation: From audit to delivery, without human intervention.
Automated Multi-Format Delivery:
- Interactive Static Site: Deployment with GitLab Pages or equivalent (with search, Mermaid, gamification, edit button, mobile navigation to read your audit on the subway, etc.)
- Complete PDF Export: All reports in one branded document for printing/archiving
- Editable Markdown Export: For separate editable doc version
- Versioned History: Audit at each commit, complete traceability
Concrete Benefits:
- Continuous Audit: Documentation updated with each code evolution
- Universal Accessibility: Interactive web, printable PDF, Markdown for e-readers
- Complete Traceability: History of audits and evolutions
- Facilitated Adoption: Standardized process, reproducible by all teams
👉 Seventh Lesson: Standardization enables team adoption.
#💡 Assessment with a Substantial Codebase
What Really Works:
- Iterative method with technical safeguards
- Multi-agent cross-validation
- Interactive documentation (Static Site > Google Doc > PowerPoint)
- Automated PDF/Markdown export
- Ready-to-Use Migration Roadmap: Once budget is approved, teams have their detailed roadmap
- Economic Optimization: CSV + architecture diagrams + Mermaid charts = agent directly consults artifacts instead of re-scanning code (cost reduction by 5-10x)
Acknowledged Limitations:
- Without technical mastery of the reviewed ecosystem, detecting hallucinations will be difficult
- No miracle: The agent doesn’t know your business context (the logical next step would be connecting it to Confluence, Notion, or similar via an MCP server)
The Near Future: Your audit reports become migration management tools. No more PowerPoints gathering dust, like a presentation from an IT service provider’s proposal. Instead, interactive roadmaps that teams consult daily.
The Visual Journey:
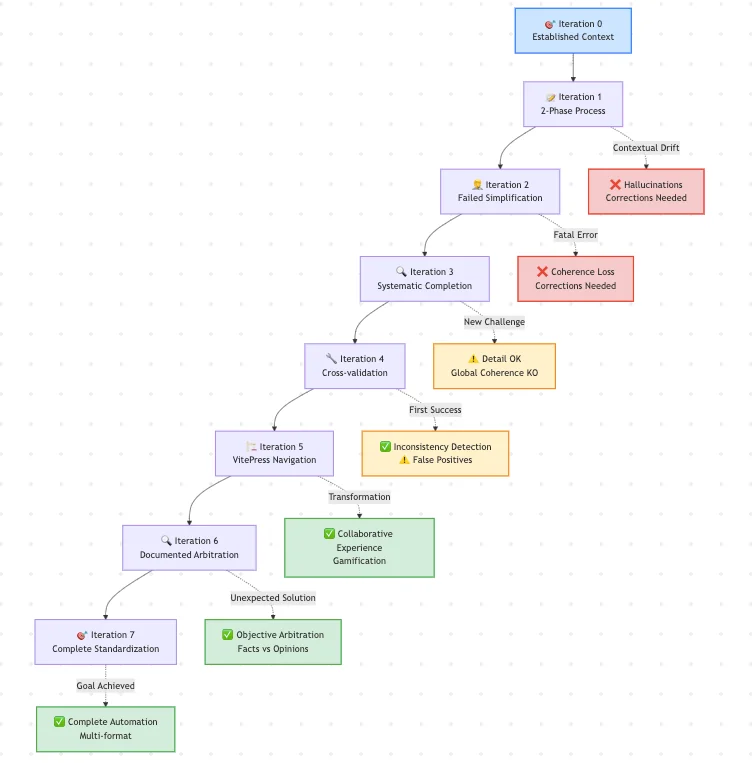
The Journey in Numbers:
- Input: 2 code repositories + pre-instructions
- Output: 417KB of interactive VitePress documentation
- Metrics: 3 weeks → 1 week, +50% technical coverage
#👨🍳 Recipe to Start Your “Vibe Pudding with a Touch of Reality”

Essential Prerequisites:
- ✅ Technical mastery of the audited ecosystem (best instructions to give the agent)
- ✅ Knowledge of the app’s business domain
- ✅ Manual audit experience (for comparison and validation)
- ✅ Standardized agent-agnostic pre-instructions file
- ✅ Ensure the project builds and runs locally (avoids auditing dead code)
- ✅ “And a pinch of patience”: a dash of patience and iterations
Recommended Stack:
- Agents: Any will do, in any form (IDE, extension, CLI, etc.). I prefer not to name names as they change monthly, as quickly as the metaverse hype. Use a different one or with a different LLM for cross-validation
- Documentation: Library for static site generation (interactive) or Markdown (simple), a format readable by both agents and humans
- Validation: Ideally know and provide a list of scanning tools that the agent will install on the audited project + CSV extraction + Mermaid architecture diagrams (bonus: the agent resumes where it left off instead of re-scanning everything and wasting tokens)
- Workflow: Monorepo with audited code + docs
Practical Advice:
- Start small: 1 project, 1 agent, systematic manual validation
- Iterate your recipe: Adjust your pre-instructions with each audit
- Document your cooking failures: Hallucinations will teach you as much as successes
#🛠️ Beyond the Audit: Your Migration Roadmap
The Real Value: The audit report isn’t a deliverable to archive. It’s your working tool for the next 6-12 months.
Concretely, once the budget is approved:
- 📋 Ready Backlog: Each recommendation becomes a ticket with estimation and priority
- 🎯 Defined Milestones: Migration steps are documented with their validation criteria
- 📊 Progress Tracking: Teams check off completed sections, the progress bar fills
- 🔍 Accessible Detail: Developer unsure about implementation? Direct access to the complete technical analysis
- 📈 Automatic Reporting: Progress status visible in real-time for management
The Unexpected Bonus: When a new dev joins the team, they read the audit report to understand technical choices. Your documentation becomes your onboarding process.
Eighth Lesson* (which will serve as a conclusion): A good audit doesn't end, it transforms into ongoing support.
Explore More